|
Yuchang Su I'm a first PhD student in Harvard AIM. Previously, I got my bachelor's degree in Computer Science and Technology at Tsinghua University. In 2024 summer, I've worked as undergraduate visiting research intern in MARVL lab at Stanford University, advised by Prof. Serena Yeung-Levy. |

|
|
CellFlux: Simulating Cellular Morphology Changes via Flow Matching
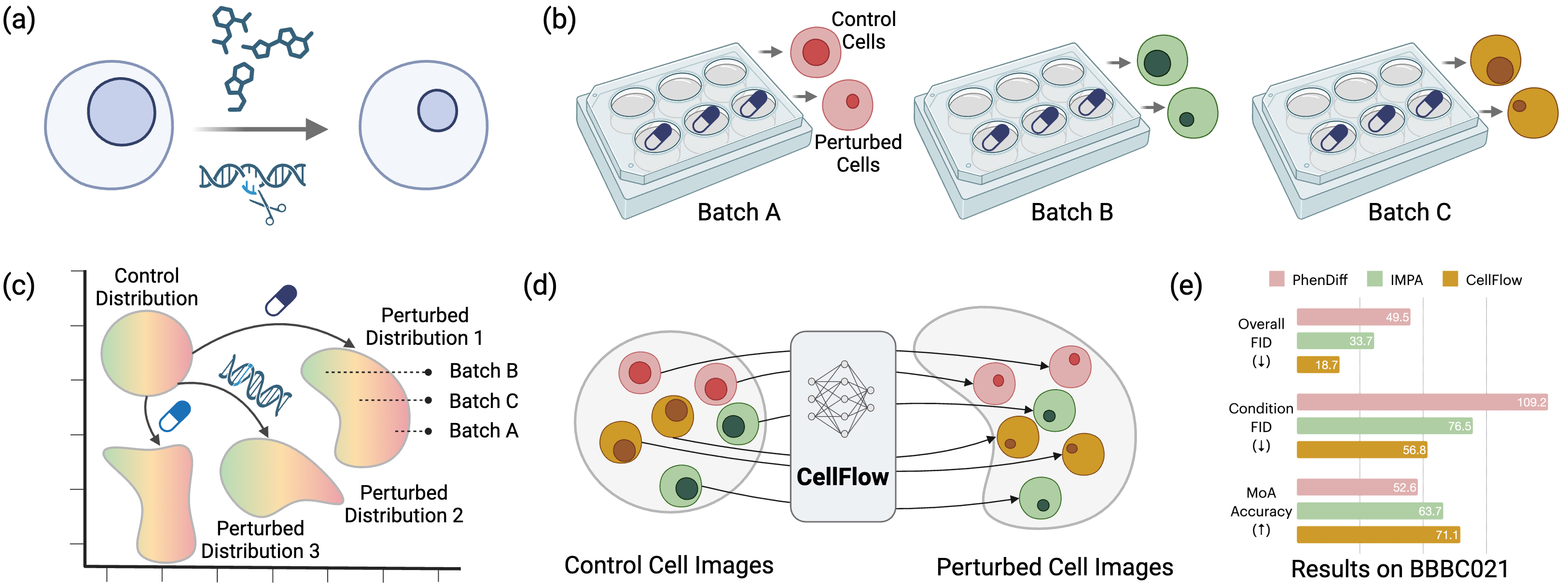
Yuhui Zhang*, Yuchang Su*, Chenyu Wang, Tianhong Li, Zoe Wefers, Jeffrey J. Nirschl, James Burgess, Daisy Ding, Alejandro Lozano, Emm Lundberg, Serena Yeung-Levy ICML 2025 arxiv *co-first authorship We introduce CellFlux, an image-generative model that simulates cellular morphology changes induced by chemical and genetic perturbations using flow matching. |
|
Automated Generation of Challenging Multiple-Choice Questions for
Vision Language Model Evaluation
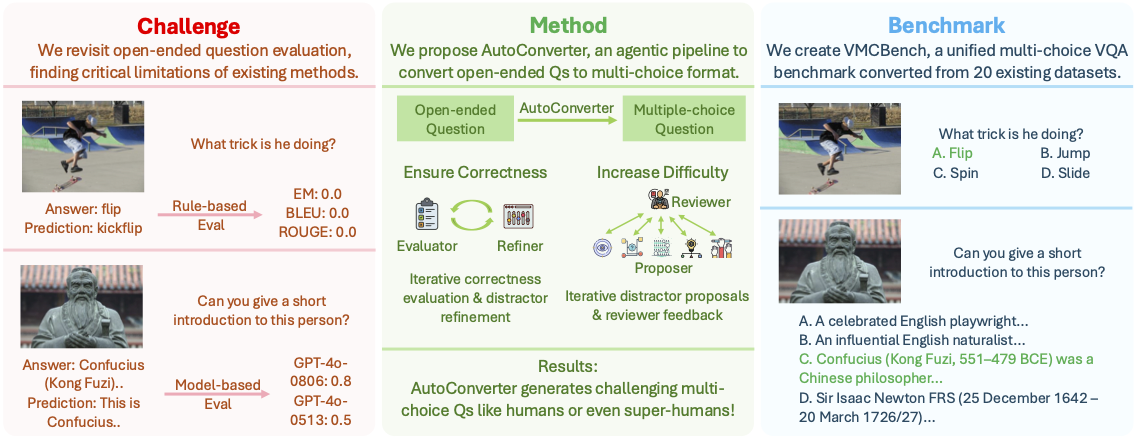
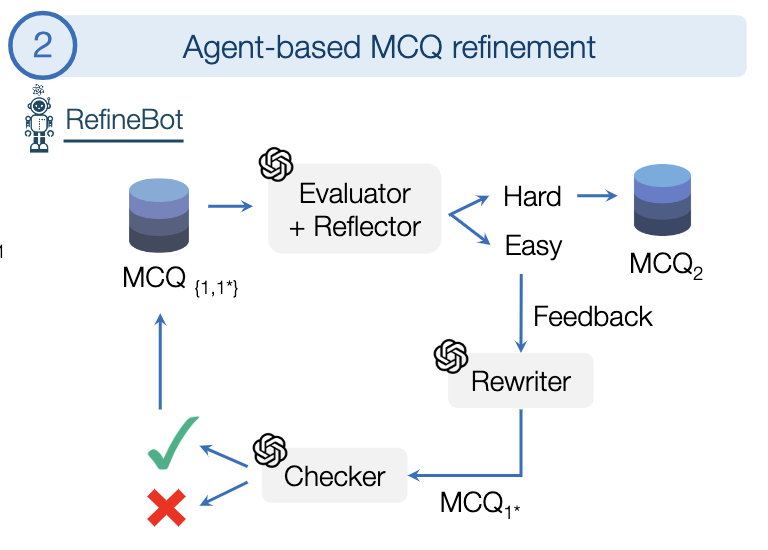
Yuhui Zhang*, Yuchang Su*, Yiming Liu, Xiaohan Wang, James Burgess, Elaine Sui, Chenyu Wang, Josiah Aklilu, Alejandro Lozano, Anjiang Wei, Ludwig Schmidt, Serena Yeung-Levy CVPR 2025 project page / arxiv / code / data *co-first authorship We introduce AutoConverter, an agentic framework that automatically converts these open-ended questions into multiple-choice format, enabling objective evaluation while reducing the costly question creation process. |

|
Converting Open-ended Questions to Multiple-choice Questions
Simplifies Biomedical Vision-Language Model Evaluation
Yuchang Su, Yuhui Zhang, Yiming Liu, Ludwig Schmidt, Serena Yeung-Levy ML4H 2024 project page / pdf / code We propose converting open-ended medical VQA datasets into multiple-choice format to address evaluation problems in medical VLMs. |
|
Multimodal Generalized Category Discovery
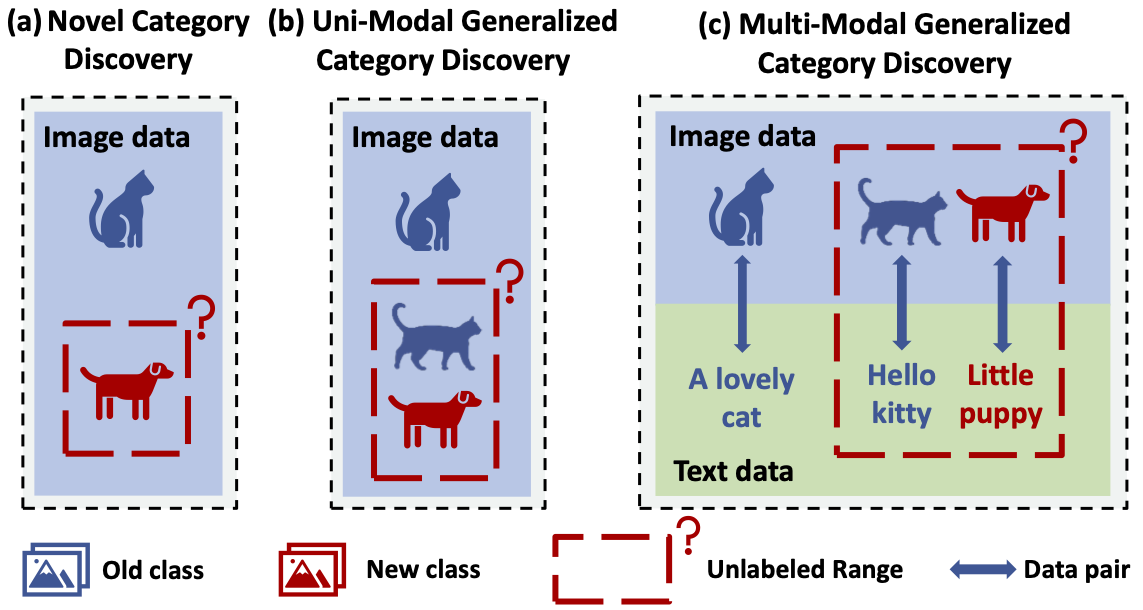
Yuchang Su, Renping Zhou, Siyu Huang, Xingjian Li, Tianyang Wang, Ziyue Wang, Min Xu CVPR Workshop 2025 arxiv We extend GCD to a multimodal setting, where inputs from different modalities provide richer and complementary information. Through theoretical analysis and empirical validation, we identify that the key challenge in multimodal GCD lies in effectively aligning heterogeneous information across modalities. To address this, we propose MM-GCD, a novel framework that aligns both the feature and output spaces of different modalities using contrastive learning and distillation techniques. |
|
NegVQA: Can Vision Language Models Understand Negation?
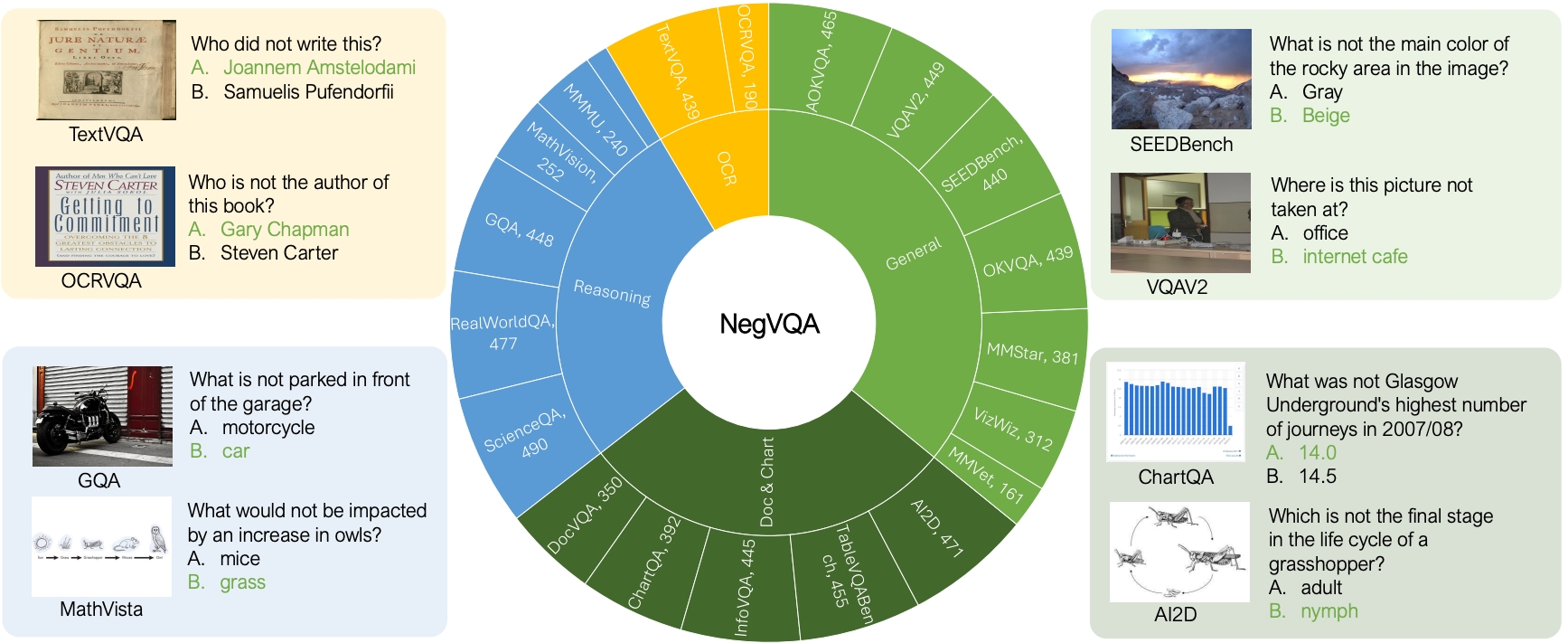
Yuhui Zhang, Yuchang Su, Yiming Liu, Serena Yeung-Levy ACL Findings 2025 We introduce NegVQA, a visual question answering (VQA) benchmark consisting of 7,379 two-choice questions covering diverse negation scenarios and image question distributions. |
|
Why are Visually-Grounded Language Models
Bad at Image Classification?
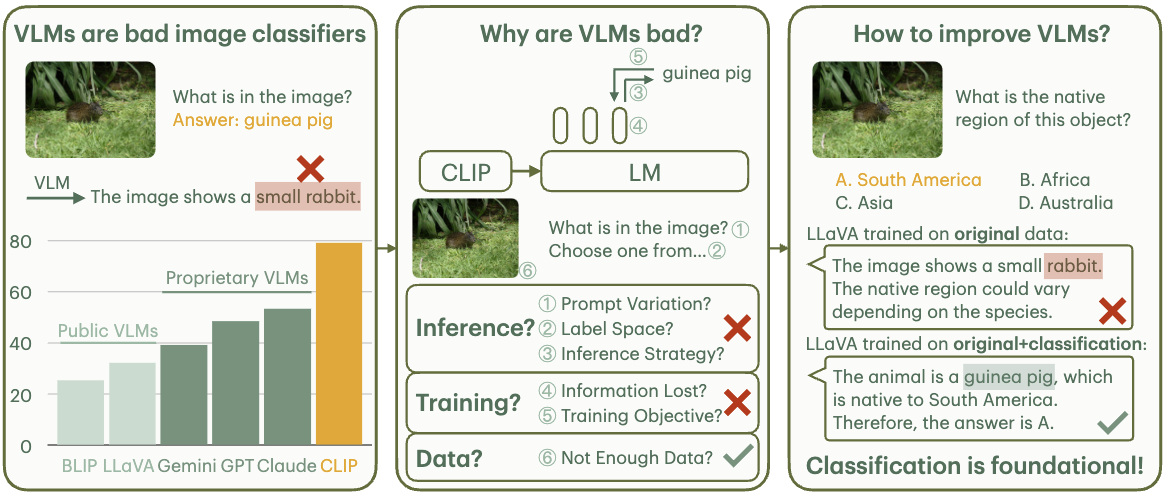
Yuhui Zhang, Alyssa Unell, Xiaohan Wang, Dhruba Ghosh, Yuchang Su, Ludwig Schmidt, Serena Yeung-Levy NeurIPS 2024 project page / arxiv / code We investigate why visually-grounded language models are bad at classification and find that the primary cause is data-related. |
|
MicroVQA: A Multimodal Reasoning Benchmark for Microscopy-Based Scientific Research
James Burgess*, Jeffrey J Nirschl*, Laura Bravo-Sánchez*, Alejandro Lozano, Sanket Rajan Gupte, Jesus G. Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, Sarina M. Hasan, Alexandra Johannesson, William D. Leineweber, Malvika G Nair, Ridhi Yarlagadda, Connor Zuraski, Wah Chiu, Sarah Cohen, Jan N. Hansen, Manuel D Leonetti, Chad Liu, Emma Lundberg, CVPR 2025 pdf / benchmark *co-first authorship MicroVQA is an expert-curated benchmark for research-level reasoning in biological microscopy. We also propose a method for making multiple-choice VQA more challenging. |